MCP总结
想要解决的问题:MCP实际上是把孤立的大模型与世界数据进行链接的一个渠道和方式。
从前为了让大模型可以与应用/数据结合,我们需要根据应用,编写特定的API,以便于大模型能够调用获取。现在MCP规范了这种API,不光针对tools,还针对llm。
MCP仅仅是一个黏合剂,他不是agent的大脑。他就是一个标准,一个工具。
MCP为什么能成功?
MCP想要解决的问题一直是存在的,并且其他公司都在尝试解决,比如LangChain,再比如OpenAI。但是MCP最终赢得了比赛,其原因可以归结在以下的几个点:
- 酒瓶装新酒,并没有完全创新,本身也是基于的LSP。
- 有A社的信用背书,并且这家公司受到开发者的青睐。
- MCP不仅仅是一个开放的标准,还直接给出了sdk和一些demo case(servers,tools)。
- A社积极在和一些公司合作,推进这个标准。标准形成了正循环。
- 刚刚好,直接到了,市面上模型的发展逐渐进入瓶颈期。
- 小步快速迭代和市场宣传。
MCP是什么,技术架构如何?
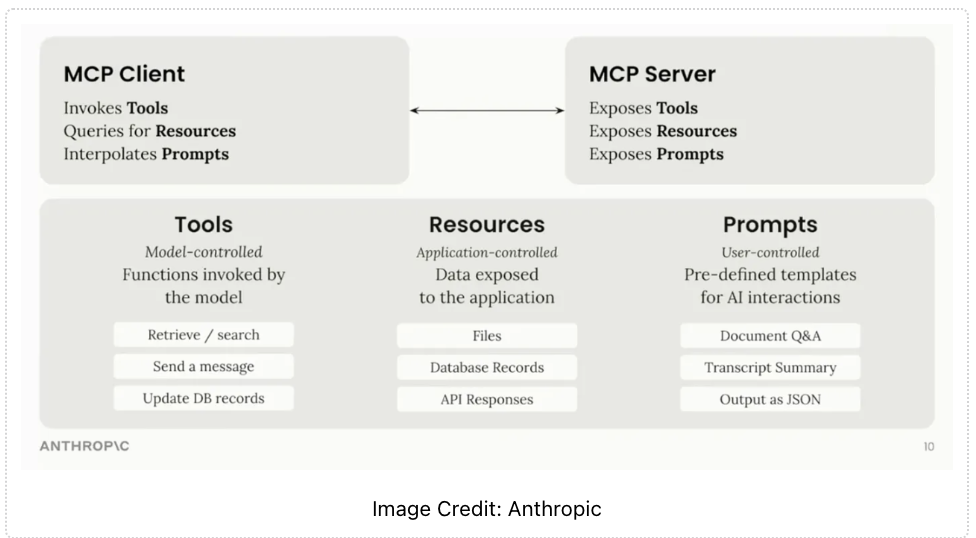
在整个MCP里面,其实存在三个主要角色:
- Host:大模型应用,发起用户请求。
- 客户端:在Host里面,与Host相链。
- 服务端:提供内容和能力。 这三个主要角色之间的交互,都是用的json。这点和LSP一模一样。
更具体的可以看上面这张图,一幕了解的给出了不同的角色做的事情。整个AI应用是自动化的发现和调用AI server的。
MCP 与传统方法的核心差异在哪里?
为了明确 MCP(Modular Capability Protocol)的定位与优势,我们可以先回顾现有常见方法的实现原理与局限性,并将 MCP 与之进行对比分析。
1. 自定义 API 的集成与调用
这类方法通常通过在应用层对接每个工具或数据源的 API。例如,开发者通过 Google Drive API 访问和操控在线文档。这种方式灵活度高,但每次集成都需要大量定制开发,缺乏标准化,无法适配更复杂的动态交互场景。
2. 基于大语言模型的插件机制
如 OpenAI 的插件体系(例如 ScholarAI),通过插件接口允许 LLM 调用外部工具。但从技术机制看,这仍是 API 调用的包装,并不具备”模型与工具”之间的深度协同能力。例如,插件本身不能感知 LLM 的内部状态,也无法与模型进行多轮交互,仍然是单向的、同步的调用过程。
3. 工具调用框架与轻量 Agent
例如 LangChain 和一些 agent 框架,将各类工具的 API 做了统一封装,提供”工具调用链”的开发便捷性。从本质看,这些框架在工具侧定义了接口标准,但缺乏对 LLM 侧行为的约束或标准化。相比之下,MCP 进一步构建了”模型侧 + 工具侧”双向的统一协议:不仅规定了工具的注册和调用方式,也规定了 LLM 如何自动决策、调度与反馈。这使得调用流程更自动化、更智能。
4. RAG 系统与向量数据库
RAG(Retrieval-Augmented Generation)方法本质上是预先构建一套内容知识库,再由模型进行查询与生成。这是一种”面向内容”的增强方式。而 MCP 的出发点是”面向能力”的组织方式,强调模型如何与不同种类的工具、数据库或外部能力进行高效交互。RAG 可以作为 MCP 的一部分被集成进来,两者并不冲突——MCP 可以统一管理多个 RAG 数据源,并提供更灵活的调度与调用机制。
MCP 是银弹吗?
本质上,MCP 是一种”协议标准”,而所有标准都不可避免地面临一些共性问题。MCP 并不是万能的解决方案,也并非”银弹”。以下是 MCP 当前需要正视的几个典型挑战:
1. 标准复杂度带来的落地门槛
部分工具虽然能够返回结构化的反馈数据,但大语言模型未必总能准确解析这些格式。如果工具方未严格遵循约定格式,或者模型端解析能力有限,就会出现”调用成功但理解失败”的情况。标准越复杂,实际兼容成本就越高,工具与模型之间的”语义鸿沟”仍然存在。
2. 标准的稳定性与兼容性问题
标准一旦发布,就需要维持相对稳定性,避免频繁调整。但 MCP 的演化速度较快,不同版本之间可能存在兼容性差异。一旦上下游工具版本不一致,就可能引发调用失败、结果失真等问题。这要求在设计标准时,既要前向兼容,也要为扩展性预留空间。
3. 场景与标准的适配程度
当前 MCP 多数实践场景集中在本地环境,尤其是在算力可控、延迟可接受的前提下效果更佳。而在云端部署、跨网络调用、多用户并发等复杂场景下,如何保持高效与稳定,仍需进一步探索与验证。标准的设计还需更好地匹配这些多样化的运行环境。
总结
MCP 的优势在于为”模型-工具”协作建立了统一的语言和行为规则。但作为标准,它仍需在实践中不断演进、快速迭代。唯有保持足够的工程灵活性与生态包容性,MCP 才能真正成为推动多智能体系统规模化应用的关键基石。